
By Vinesh Jha, CEO & founder of ExtractAlpha
In my previous post, I discussed some of the benefits of systematic investing. In this post, we will take a look at a few pitfalls.
Systematic investing typically relies on backtesting. This is the process of stepping through historical data and seeing how a strategy would have performed if it had been used at the time. However, backtesting is not without its pitfalls.
There’s a really nice presentation by Deutsche Bank’s former quant research team on this topic, which I’d encourage everyone to read. Most of the things I’ll mention here are discussed there too, with perhaps a slightly different take.
Sample size matters
The first issue is sample size. Many quants we talk to ask for 5 to 10 years of historical data before they will consider backtesting a new strategy or factor. Unfortunately many of the most interesting new alternative datasets simply don’t have that much history available. For example, ExtractAlpha’s Transcripts Model – Asia is based on earnings call transcripts for Japan and Greater China which simply weren’t available 10 years ago. So we need to make compromises in some cases. The 5-10 year minimum should really be considered more of a guideline than a rule. If you’re working on very high frequency data, for example, you’ll get plenty of data points within just one year of data, and if you’re looking at macroeconomic effects, you may not experience a sufficient diversity of regimes within a single decade – so your backtest may not capture a broad enough range of possible future conditions.
I wish I had a time machine
Of course, things have changed substantially in ten years. We’ve been through high and low volatility regimes, trading costs have come down, and quant investing has become more competitive. We’ll discuss some good practices for taking those issues into account in the next post. For now we will mention two related dangers of looking back several years: lookahead bias and its pernicious special case, survivorship bias.
Lookahead bias refers to the practice of assuming that we would have known something historically which we did not in fact know. A cynic could argue that all backtesting is an exercise in lookahead bias, but we can certainly control for certain aspects of lookahead in our test design. For example, quarterly financials are not reported immediately after a company’s fiscal quarter ends, and if we don’t make conservative enough assumptions about the data’s historical availability, we may “peek ahead” into the future in assuming we know the health of a company’s balance sheet before it was made available. Having accurately timestamped data – and knowing what time zone that timestamp is in! – is a good way to avoid lookahead bias.
Lookahead can manifest in other, sneakier ways too; one common culprit is data which is presented as static but which really should be stored as a time series. The classic example is index membership. Let’s suppose we want to test whether the stocks in the S&P 500 with tickers starting with the letter A typically outperform. If we take the current 500 members and select out the A’s, we can build a portfolio of those stocks and compare it to the S&P 500 index. Here we go:
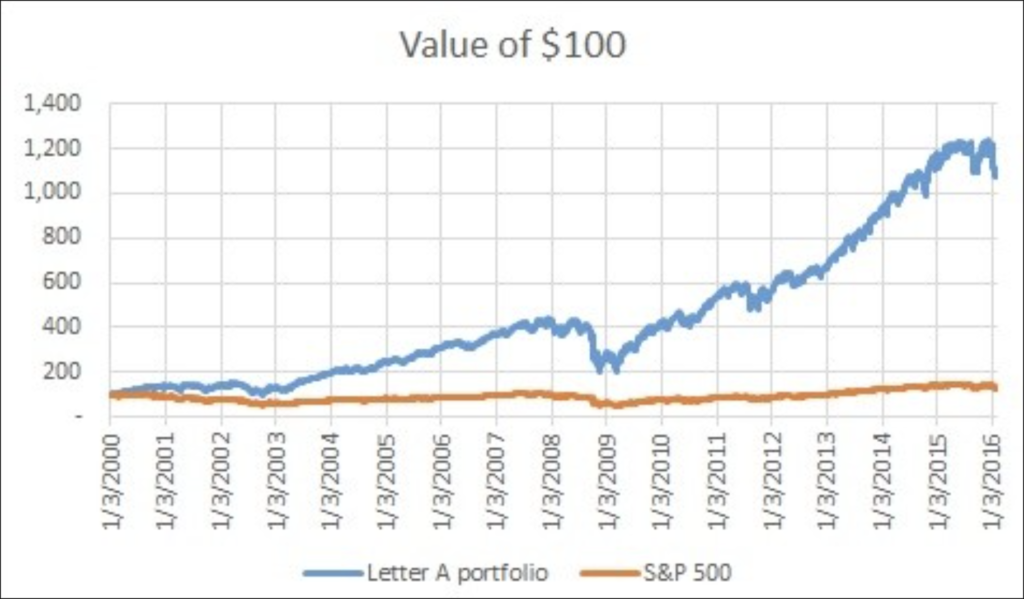
Pretty awesome, right? We beat the benchmark handily! But of course we didn’t know back in January 2000 which stocks would be in today’s S&P 500, and the fact that they survived to become large caps means that almost by definition they did relatively well over this period, regardless of what letters were in their ticker symbols. That’s survivorship bias, one of the most common errors for a new quant to make, and the term for a dataset which does not exhibit survivorship bias is point-in-time (PiT). I talked about a more ESG-flavored variant of this issue in this post which questions the WSJ’s claim that more diverse companies outperform.
As an aside, there’s another problem with my backtest here: I’m comparing an equally weighted portfolio to a cap-weighted index. If the smaller names in the portfolio outperformed the larger names which dominate the index, that could cause apparent outperformance that’s not really attributable to our strategy. It’s always worth thinking about what the right benchmark should really be; for example, I often see long/short portfolios nonsensically benchmarked against a long-only index.
Reality check
I’m a big fan of scanning academic research for idea generation, but academics tend to ignore some realities which practitioners simply can’t. We can’t ignore transaction costs and market impact; we may find a factor which seems to predict returns very nicely over short horizons, but if we trade large quantities of capital too quickly we’ll move the market against us and will generate excessive trading costs. And if we don’t act quickly enough on such a factor because our trading process exhibits too much latency, the factor’s efficacy may decay. (Fast moving factors can still be useful in a long horizon strategy if implemented correctly, though).
Furthermore, if we have a strategy which includes short sales, we may not be able to realistically borrow sufficient amounts of the stocks we need, if the demand for borrow exceeds the supply. This is a somewhat difficult thing to simulate historically, but we can make assumptions about our universe which can mitigate the effects of this shortcoming somewhat. We’ll touch on that in the next post too.

Monkey business
The final pitfall I’ll mention is perhaps the hardest one to overcome: the risk of overfitting a model. Part 1’s example of butter in Bangladesh is related to overfitting: Leinweber sifted through economic variables until he found one which spuriously explained the S&P 500. Similarly, if we try a sufficient number of factors and a sufficient number of parametrizations of those factors, we will eventually find the proverbial monkey at a typewriter who seems to have written Shakespeare. What’s the likelihood that he will continue to write Shakespeare going forward?
The best controls for overfitting are hypothesis development and parsimony. We should have a good economic or behavioral intuition for why a factor should work or not work, and then model it in a simple way. We can then run some sensitivity analysis to make sure we haven’t stumbled upon a randomly good parametrization, but simple expressions of an idea tend to be more robust than complex ones. This holds even if we are utilizing advanced machine learning techniques.
In summary
The pitfalls you can avoid while backtesting are:
- Sample size: Using a backtest with a small sample size can lead to inaccurate results The minimum recommended sample size is 5-10 years, but this may vary depending on the strategy and the market conditions
- Lookahead bias: This is the backtesting pitfall of using information that was not available at the time you are simulating. This can lead to inflated returns and unrealistic expectations
- Survivorship bias: This is a special case of Lookahead Bias where, in a backtest, we use information on what companies or other entities later survived (or thrived or failed), which was not known at the time.
- Transaction costs: Backtests often do not take into account the costs of trading, such as commissions and slippage. This can significantly reduce the returns of a strategy
- Overfitting: This is the practice of fitting a model too closely to the historical data. This can lead to a model that performs well in the backtest but does not generalize well to new data
I hope you found this discussion of pitfalls useful. In the next and final post of the series, I cover some best practices for successful systematic investment research.
